
python의 대표적인 딥러닝 라이브러리인 PyTorch lightning에 대해 살펴보고자 합니다.
목차
1. pytorch lightning이란
2. 딥러닝 flow
3. pytorch lightning 샘플코드 모델 소개
4. pytorch lightning 샘플코드 - 전체
5. 샘플코드 살펴보기 - 1) 라이브러리 확인
6. 샘플코드 살펴보기 - 2) dataset 준비
7. 샘플코드 살펴보기 - 3) model 정의
8. 샘플코드 살펴보기 - 4) 모델학습
9. 샘플코드 살펴보기 - 5) 모델평가
10. 샘플코드 살펴보기 - 6) 모델적용/사용
11. 총평
1. PyTorch lightning이란
먼저, PyTorch는 https://devscb.tistory.com/104 에서 소개한 바와 같이, Python기반의 오픈소스 머신 러닝 라이브러리입니다. 자연어 처리, 딥러닝 등을 구현하기 위한 라이브러리이며, GPU 사용을 통해 빠른 연산이 가능합니다.
FaceBook (Meta)에서 만들어졌습니다.
PyTorch Lightning이란 딥 러닝 프레임워크인 PyTorch에 대한 고급 인터페이스를 제공하는 오픈 소스 Python 라이브러리입니다.high level API를 제공함으로써 효율적이고 정돈된 code style로 코딩이 가능합니다.
PyTorch Lightning은 아래와 같이 PyTorch보다 더 짧은 코드 구현으로 deep learning model을 설계할 수 있습니다.

또한, Pytorch Lightning은 GPU, TPU, 16bit연산, 분산학습 등 지원을 강화하였습니다.
Pytorch는 종종 keras(tensorflow)와 비교되기도 하는데요, 주 사용처는 다음과 같습니다.
keras : 검증된 기법 / 모델을 응용하고 상용모델을 배포하기 위해 많이 씁니다.
PyTorch : 빠른 실험과 정교한 튜닝, 연구용 모델 등 시험적인 상황에서 많이 사용합니다.
2. 딥러닝 모델 설계 흐름, deep learning model 설계 flow
딥러닝 모델 설계 흐름은 일반적으로 아래와 같이 단순히 표현할 수 있습니다.
1. DataSet준비 (데이터 정제 등 포함)
2. Model 정의
3. Model 학습
4. Model 평가
5. Model 시험/적용
3. pytorch lightning 샘플코드 모델 소개
이 글에서는 pytorch lightning 샘플코드 모델을 소개하고자 합니다.
샘플코드는 필기체 숫자를 판단하는 모델을 설계합니다.
데이터는 MNIST dataset이라는 이미지를 사용하며, 아래모양과 같습니다.
이 dataset은 이미 labeling이 되어 있으며, 새로운 필기체 데이터가 들어오면,
어떤 숫자인지 판단하는 모델을 만들고자 합니다.
그림으로 도식화하면 아래와 같이 표시할 수 있습니다.
data & labels 는 이미 준비되어 있고, network training 부분을 모델링하도록 합니다.
출력값은 0부터 9까지 중 하나의 값이 됩니다.

4. pytorch lightning 샘플코드 - 전체
pytorch lightning을 사용한 샘플코드를 소개해보고자 합니다.
전체 소스 코드는 아래와 같습니다.
#!pip install pytorch_lightning torchinfo torchmetrics torchviz
import torch
from torch import nn
import pytorch_lightning as pl
from torchmetrics import functional as FM
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def dataLoader(batch_size=128):
train_dataset = MNIST('', transform=transforms.ToTensor(), train=True, download=True)
val_dataset = MNIST('', transform=transforms.ToTensor(), train=False, download=True)
trainDataLoader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valDataLoader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
return (trainDataLoader,valDataLoader)
trainDataLoader,valDataLoader = dataLoader()
loss_function = nn.CrossEntropyLoss()
class MyModel(pl.LightningModule):
def __init__(self, num_classes):
super(MyModel, self).__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, num_classes) )
self.num_classes = num_classes
def forward(self, x):
out = self.layers(x)
return out
def training_step(self, batch, batch_idx):
x, y = batch
y_pred = self(x)
loss = loss_function(y_pred, y)
acc = FM.accuracy(y_pred, y, task='multiclass', num_classes=self.num_classes)
self.log_dict({'loss':loss, 'acc':acc})
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_pred = self(x)
loss = loss_function(y_pred, y)
acc = FM.accuracy(y_pred, y, task='multiclass', num_classes=self.num_classes)
self.log_dict({'val_loss':loss, 'val_acc':acc})
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
model_name = 'MyModel'
epochs = 15
logger = pl.loggers.CSVLogger("logs", name=model_name)
trainer = pl.Trainer(max_epochs=epochs, logger=logger, accelerator="auto")
model = MyModel(10)
trainer.fit(model, trainDataLoader, valDataLoader)
class Ploter():
#def __init__(self):
def add_plot(label, df):
plt.plot(df, linestyle='-', label=label)
def plot():
plt.legend()
plt.grid()
plt.show()
logger_version = logger.version
history = pd.read_csv(f'./logs/{model_name}/version_{logger_version}/metrics.csv')
df = history.groupby('epoch').mean().drop('step', axis=1)
for metric in ['loss', 'acc', 'val_loss', 'val_acc']:
Ploter.add_plot(metric, df[metric])
Ploter.plot()
model.eval()
train_features, train_labels = next(iter(valDataLoader))
y_predict = model(train_features[0]) # model <- image only
print('-----predict----')
print(y_predict)
print(np.argmax(y_predict[0,:].detach()))
print('-----real----')
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
[실행결과]
INFO:pytorch_lightning.utilities.rank_zero:GPU available: False, used: False
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
INFO:pytorch_lightning.callbacks.model_summary:
| Name | Type | Params
--------------------------------------
0 | layers | Sequential | 7.9 K
--------------------------------------
7.9 K Trainable params
0 Non-trainable params
7.9 K Total params
0.031 Total estimated model params size (MB)
Epoch 14: 100%
548/548 [00:13<00:00, 39.18it/s, loss=0.247, v_num=1]INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=15` reached.

-----predict----
tensor([[-1.6204, -5.3632, -1.4565, 0.6515, -2.2311, -2.1226, -4.6138, 6.0681,
-1.5127, 1.1087]], grad_fn=<AddmmBackward0>)
tensor(7)
-----real----

Label: 7
다음부터는 코드를 부분부분 나누어 좀 더 자세히 설명해보겠습니다.
5. pytorch lightning이란샘플코드 살펴보기 - 1) 라이브러리 확인
전체 소스중 라이브러리가 필요한 코드부분입니다.
pip 를 이용해서 pytorch_lightning torchinfo torchmetrics torchviz 를 인스톨해줍니다.
torch : pytorch사용을 위함
pytorch_lightning : pytorch 를 좀 더 쉽게 사용하기 위한 pytorch lightning
torchmetric : accuracy 계산을 쉽게 하기위해 사용하고자 합니다.
torchvision.transforms : data를 pytorch model이 이해할 수 있도록 변환시키고자 사용하고자 합니다.
DataLoader : data를 쉽게 불러오게 하기 위함입니다.
MNIST : 이번 글에서 다룰 데이터입니다.
numpy, pandas : python에서 데이터를 다루기 위한 기본적인 라이브러리입니다.
matplotlib.pyplot : 그래프를 그리기 위해 필요한 기본적인 라이브러리입니다.
#!pip install pytorch_lightning torchinfo torchmetrics torchviz
import torch
from torch import nn
import pytorch_lightning as pl
from torchmetrics import functional as FM
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
6. 샘플코드 살펴보기 - 2) dataset 준비
MNIST() 함수를 이용하여 데이터셋을 준비해줍니다.
train = True일 경우, train-images-idx3-ubyte로부터 생성하며,
False일 경우 t10k-images-idx3-ubyte 로부터 생성합니다.
transforms.ToTensor를 해주어야 머신러닝을 진행할 수 있습니다.
DataLoader 함수는 데이터를 받아들이고, 배치사이즈와 shuffle 여부를 정할 수 있습니다.
결론적으로 학습시킬데이터를 가져오고, 그 중 일부분을 모델을 평가하는데 사용하는 valData로 사용하고자 합니다.
def dataLoader(batch_size=128):
train_dataset = MNIST('', transform=transforms.ToTensor(), train=True, download=True)
val_dataset = MNIST('', transform=transforms.ToTensor(), train=False, download=True)
trainDataLoader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valDataLoader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
return (trainDataLoader,valDataLoader)
trainDataLoader,valDataLoader = dataLoader()
7. 샘플코드 살펴보기 - 3) model 정의
본격적인 model 을 설계하는 코드입니다.
pl.LightningModule 을 상속받아 구현할 수 있습니다.
__init__은 초기화 메소드입니다, 학습을 진행하기 위한 모델을 설계합니다.
Lightning Module class에서 사용할 모델을 정의 합니다. Pytorch에 신경망 Layer를 생성하려면, torch.nn.module을 사용해야합니다.
forward는 추론에 사용됩니다. forward는 모델의 추론 결과를 제공하고 싶을 때 사용합니다.
training_step 은 forward와 유사하지만, loss를 반환해야합니다.
loss를 구하는 방법은 mse, cross entropy등 다양하게 측정하는 방법이 있습니다.
또한, training_step은 진행할 때마다 각 신경의 weight가 업데이트 됩니다.
validataion_step은 학습 중간에 모델의 성능을 확인하는 용도로 사용합니다. 배치를 통해 validation 데이터를 가지고 확인하고자 하는 통계량을 기록하기위해 사용합니다.
만약에 각 validation_step의 결과로 무엇인가 할 일이 있으면 validation_epoch_end 메서드를 추가로 작성할 수 있습니다.
configure_optimizers는 모델의 최적 파라미터를 찾을 때 사용할 optimizer와 learning rate scheduler를 구현합니다.
optimizer는 loss값을 최소화하기 위한 메소드를나타내며, rmsprop, adam 등을사용합니다.
learnig rate scheduler는 learning rate를 batch마다 변경하기 위해 정의할 수 있습니다.
loss_function = nn.CrossEntropyLoss()
class MyModel(pl.LightningModule):
def __init__(self, num_classes):
super(MyModel, self).__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, num_classes) )
self.num_classes = num_classes
def forward(self, x):
out = self.layers(x)
return out
def training_step(self, batch, batch_idx):
x, y = batch
y_pred = self(x)
loss = loss_function(y_pred, y)
acc = FM.accuracy(y_pred, y, task='multiclass', num_classes=self.num_classes)
self.log_dict({'loss':loss, 'acc':acc})
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_pred = self(x)
loss = loss_function(y_pred, y)
acc = FM.accuracy(y_pred, y, task='multiclass', num_classes=self.num_classes)
self.log_dict({'val_loss':loss, 'val_acc':acc})
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
8. 샘플코드 살펴보기 - 4) 모델학습
모델 학습은 trainer를 초기화하고, trainter.fit에 train / validataion dataloader와 모델을 넣어주면 학습이 진행됩니다.
그 외에 추가적으로 학습이 진행되는 경과를 확인하기 위해 logger를 사용하였습니다.
epoch를 진행하면서 학습이 진행되나, 어느 순간부터는 loss값이 더 이상 줄어들지 않게 되기에 적절한 값을 정해주어야 합니다.
model_name = 'MyModel'
epochs = 15
logger = pl.loggers.CSVLogger("logs", name=model_name)
trainer = pl.Trainer(max_epochs=epochs, logger=logger, accelerator="auto")
model = MyModel(10)
trainer.fit(model, trainDataLoader, valDataLoader)
9. 샘플코드 살펴보기 - 5) 모델평가
이번 예제에서는 모델 평가를 하기 위해 모델 학습시 진행한 csv 로깅파일을 사용하였습니다.
pytorch의 로거를 사용하면 ./logs/{model_name}/version_{logger_version}/metrics.csv 파일에 기록이 됩니다.
버전은 fit()을 할 때마다 update되며, 모델명은 지정해준 이름으로 생성이됩니다.
로깅시, loss, acc, val_loss, val_acc는 모델 정의시 해당 값들을 로깅하도록 하였습니다.
class Ploter():
#def __init__(self):
def add_plot(label, df):
plt.plot(df, linestyle='-', label=label)
def plot():
plt.legend()
plt.grid()
plt.show()
logger_version = logger.version
history = pd.read_csv(f'./logs/{model_name}/version_{logger_version}/metrics.csv')
df = history.groupby('epoch').mean().drop('step', axis=1)
for metric in ['loss', 'acc', 'val_loss', 'val_acc']:
Ploter.add_plot(metric, df[metric])
Ploter.plot()
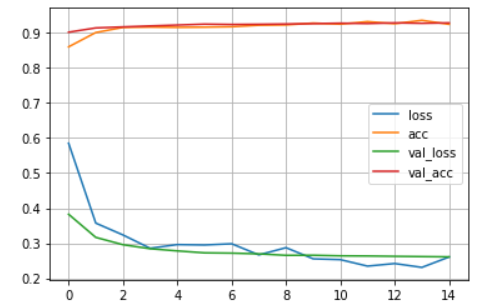
csv파일의 내용은 아래와 같습니다.

또한, 이를 통해 plot 함수를 사용하여 그래프를 그려보면 아래와 같습니다.
학습이 진행되면서 loss는 줄고, accuracy는 올라가는것을 확인할 수 있습니다.
이 그래프를 보고 확인하면서 어느시점까지 학습을 진행해야할지 판단할 수 있습니다.
10. 샘플코드 살펴보기 - 6) 모델적용/사용
학습이 완료된 모델을 사용하기 위해서는 model.eval() 을 호출해주도록 합니다.
model.train(False)와 동일한 역할을 하며, 일부 layer를 비활성화 합니다.
비활성화하는 대표적인 layer로는 dropout, batchNorm 등이 있습니다.
model에 data를 파라미터로 넣어주면 예측한 결과를 출력해주도록 합니다.
이번 코드에서는 예측한 값과 실제값, 실제 이미지가 어떤 것인지 살펴보았습니다.
대표적인 하나의 예시를 살펴보니 모델이 잘 동작하는것을 확인할 수 있습니다.
model.eval()
train_features, train_labels = next(iter(valDataLoader))
y_predict = model(train_features[0]) # model <- image only
print('-----predict----')
print(y_predict)
print(np.argmax(y_predict[0,:].detach()))
print('-----real----')
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
출력 결과 내용을 보았을때, 0부터 9까지중 7일 확률이 제일 높은것으로 (6.0681) 확인하여 7로 예측하였으며, 이미지를 확인하고 label된 값을 보았을 때, 잘 예측된 값이라고 확인할 수 있습니다.

11. 총평
제가 처음 딥러닝을 배웠을 때에 보다 훨씬 코드 수가 적어서 편하게 모델을 설계하고 사용할 수 있었습니다.
처음 접하게 된게 2015~2016년 쯔음이었던걸로 기억하는데, 그 사이에 엄청나게 또 많은것이 변한것 같기도 합니다.
그럼에도 불구하고, 여전히 많은 라이브러리를 import를 해야하여 사용하는 점이 살짝 아쉽습니다.
또한, 내부 내용이 추상화되어있는게 너무 많고 설정해야하는 값들이 많아 코드수는 적지만 구체적인 hyper paramter, 메소드를 어떤것을 써야하는지는 많이 어려운 부분같습니다. 이 부분에 대해서는 autoML 분야가 좀 더 진행이 되어 머신러닝을 좀 더 쉽게 사용할 수 있는 날이 왔으면 좋겠습니다.
또한, 머신러닝에 관한 이론에 대해서도 공부해보고 추후 다뤄볼 수 있도록 해보겠습니다.
#microsoft,#wpf,#button,#checkbox,#label,#underscore,#under,#score,#windows,#presentation,#foundation,#마소,#마이크로소프트,#버튼,#체크박스,#언더스코어,#밑줄,#라벨,#레이블
Starting deep learning with pytorch lightning, look at pytorch lightning sample code
We would like to take a look at PyTorch lightning, a representative deep learning library in Python. What is PyTorch lightning?First, PyTorch is a Python-based open source machine learning library, a
devscb.com




댓글